The Privacy-Latency Trade-Off
For years, real-time translation lived in the cloud. Smartphone users spoke into their devices, audio traveled to remote servers, large language models processed the text, and translations streamed back. The results were impressive in quality but problematic in practice: latency varied with network conditions, privacy demanded sending conversations to third-party servers, and offline scenarios made translation impossible.
The alternative—running translation models entirely on-device—seemed impossible until recently. Transformer models, the architecture powering modern translation, contain hundreds of millions to billions of parameters. Running such models on mobile processors would drain batteries, generate heat, and produce unacceptable latency.
Yet today, real-time on-device translation is not only possible but increasingly common. The breakthrough lies in transformer model compression—techniques that shrink models by 10-100x while preserving accuracy—combined with mobile NPUs (neural processing units) optimized for transformer inference. This article explores how compression enables translation models to fit in memory, execute in milliseconds, and preserve user privacy.
The Transformer Architecture: Why It’s Hard to Compress
Transformers, introduced in the 2017 paper “Attention Is All You Need,” revolutionized machine translation. Their architecture—stacked encoder and decoder layers with multi-head attention—achieves state-of-the-art accuracy but demands substantial compute and memory.
A typical translation transformer contains:
- 6-24 encoder layers: Each with multi-head attention and feed-forward networks
- 6-24 decoder layers: Similar structure with cross-attention
- Embedding layers: Large matrices mapping tokens to vectors (typically 512-1024 dimensions)
- Total parameters: 50 million to 1 billion
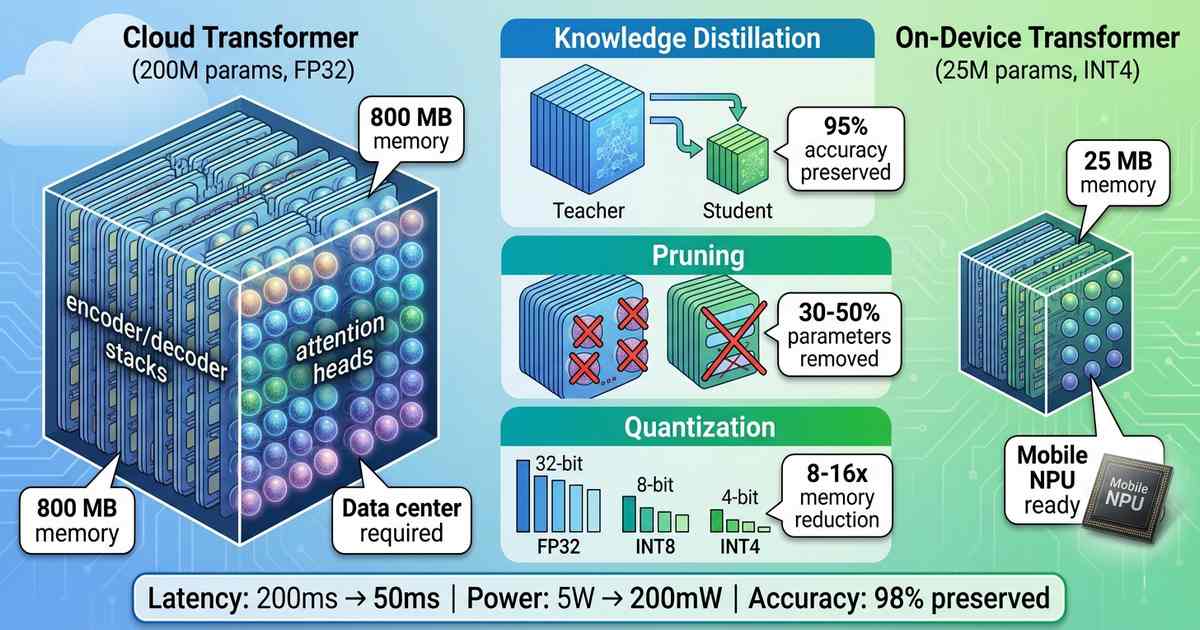
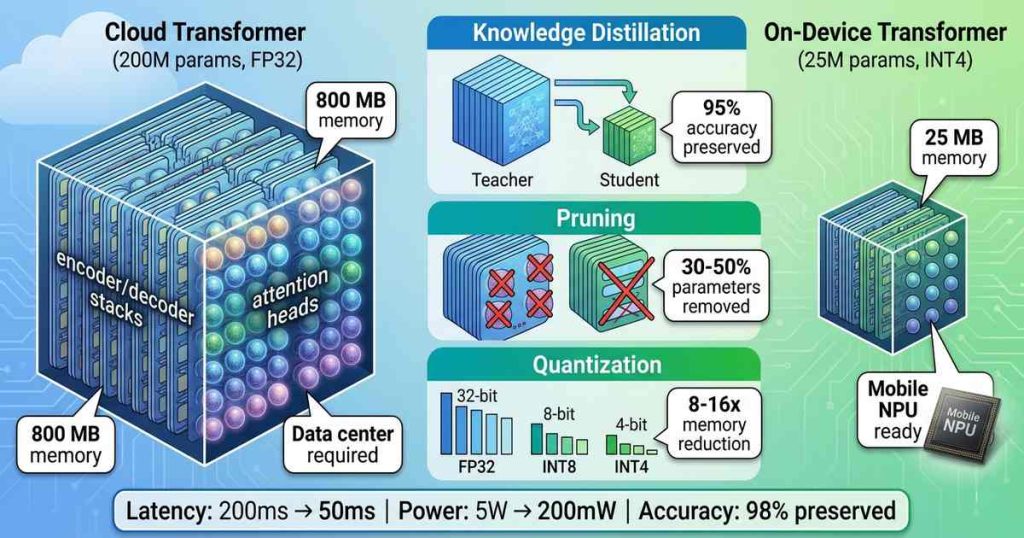
At full precision (32-bit), a 200 million parameter model occupies 800 MB of memory—too large for many mobile devices and certainly too large for the 1-5 MB typically allocated to NPU models. Inference latency on a mobile CPU can reach seconds per sentence, unacceptable for real-time conversation.
Model Compression: The Three Pillars
Three complementary techniques reduce transformer models for mobile deployment:
Quantization: Reducing Precision
Quantization reduces the precision of model weights and activations from 32-bit floating point to 8-bit, 4-bit, or even lower. A 4-bit quantized model uses 8x less memory than its 32-bit counterpart.
Post-training quantization (PTQ) applies quantization after training, requiring no retraining. While simple, PTQ can degrade accuracy for complex tasks like translation. Quantization-aware training (QAT) simulates quantization during training, allowing the model to adapt and preserve accuracy. QAT-quantized transformers typically lose less than 1% BLEU score while achieving 4-8x compression.
For mobile NPUs, 8-bit integer (INT8) quantization has become standard. Most mobile NPUs—from Qualcomm Hexagon, MediaTek APU, and Apple Neural Engine—are optimized for INT8 operations, achieving 2-4x higher throughput than FP16. Emerging NPUs support 4-bit integer (INT4), enabling 8x compression with minimal accuracy loss.
Pruning: Removing Redundant Parameters
Neural networks are massively overparameterized. Pruning removes weights, neurons, or attention heads that contribute little to output.
Magnitude pruning removes weights with small absolute values. Structured pruning removes entire attention heads or feed-forward dimensions, yielding models that run faster on NPUs without specialized sparse hardware.
For translation transformers, pruning can remove 30-50% of parameters with minimal accuracy loss. The key insight: not all attention heads are equally important. Many heads attend to redundant patterns and can be eliminated. Pruned models require fine-tuning to recover accuracy.
Knowledge Distillation: Learning from the Teacher
Knowledge distillation trains a small “student” model to mimic a larger “teacher” model. The student learns not just correct outputs but the teacher’s probability distributions, capturing subtle linguistic patterns.
For translation, distillation is remarkably effective. A 50 million parameter student trained from a 200 million parameter teacher achieves 95-98% of the teacher’s BLEU score while being 4x smaller and 3-5x faster. Multi-stage distillation—training progressively smaller models—can produce viable models under 10 million parameters.
Mobile NPUs: Optimized for Compressed Transformers
Mobile NPUs are specialized accelerators designed for neural network inference. Unlike CPUs or GPUs, NPUs use:
- Systolic arrays: Dense matrix multiplication engines optimized for transformer feed-forward layers
- Memory hierarchies: On-chip SRAM that stores weights and activations, minimizing off-chip DRAM access
- Sparse support: Hardware that efficiently handles pruned models by skipping zero-weight operations
- Quantization pipelines: Native INT4/INT8 operations with hardware dequantization
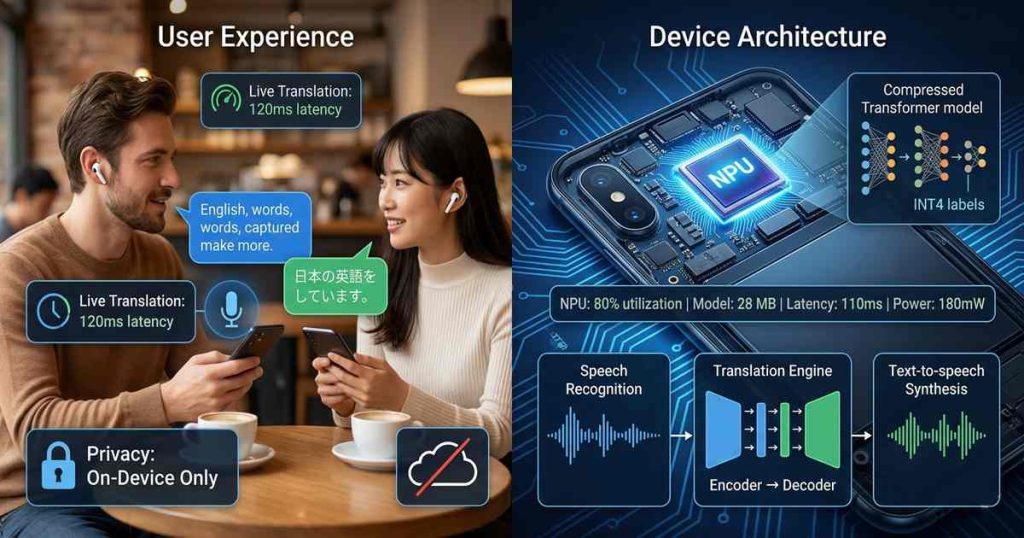
The combination of compression and NPU acceleration is transformative. A 100 million parameter transformer at INT4 (50 MB) running on a flagship NPU achieves:
- Latency: 50-200 ms per sentence
- Power: 100-300 mW (versus 2-5W on CPU)
- Memory bandwidth: 5-10x reduction through compression
These numbers enable real-time conversation—processing spoken phrases as they complete, with latency below human perception thresholds.
Implementation Pipeline: From Cloud to Edge
Deploying an on-device translation model follows a structured pipeline:
1. Teacher training: Train a full-precision transformer on parallel corpora (e.g., 200M parameters, FP32)
2. Distillation: Train a smaller student model (50-100M parameters) using teacher outputs
3. Pruning: Remove unimportant attention heads and feed-forward dimensions (30-50% reduction)
4. Quantization-aware training: Retrain with INT8 or INT4 simulation to recover accuracy
5. NPU compilation: Convert to NPU-specific format (Qualcomm SNPE, MediaTek NeuroPilot, Apple CoreML)
6. On-device integration: Package with speech recognition and text-to-speech for full translation pipeline
The entire process takes days to weeks, yielding a model that fits in 20-100 MB and executes in milliseconds.
Real-World Implementations
Google Translate’s On-Device Mode: Google’s translation models now support offline translation for 100+ languages using compressed transformers. The models, typically 30-80 million parameters at INT8, run on Pixel NPUs and deliver translation in under 200 ms per sentence.
Samsung Galaxy AI Live Translate: Samsung’s 2024 Galaxy phones introduced live translation for voice calls using on-device models. The system combines speech recognition, translation, and synthesis in under 500 ms end-to-end—all running locally on the Exynos NPU.
Apple Translate: Apple’s translation framework uses distilled transformers (approximately 20-40 million parameters) optimized for Neural Engine. Offline translation is seamless across iOS devices with no perceptible latency.
Meta’s No Language Left Behind (NLLB): Meta’s open-source translation models include distilled variants down to 10 million parameters targeting edge deployment. The smallest models run on mobile NPUs while maintaining 90% of full-model accuracy for 100+ languages.
Accuracy vs. Compression Trade-Offs
The relationship between compression and accuracy is nonlinear:
- 4x compression (200M → 50M): <1% BLEU loss, 2-3x latency improvement
- 8x compression (200M → 25M): 2-5% BLEU loss, 4-6x latency improvement
- 16x compression (200M → 12M): 5-10% BLEU loss, 8-10x latency improvement
For most consumer applications, 4-8x compression strikes the optimal balance. Users rarely notice the small quality difference, while the latency and privacy benefits are substantial.
Privacy: The Unspoken Advantage
On-device translation offers a fundamental privacy advantage over cloud alternatives. Conversations never leave the device:
- No audio transmitted to servers
- No text logged in cloud databases
- No third-party access to sensitive conversations
For business travelers discussing proprietary information, healthcare professionals consulting with patients, or individuals in sensitive contexts, this privacy guarantee is determinative. On-device translation is the only option that ensures conversations remain completely private.
Future Directions
4-bit and 2-bit quantization: Emerging NPUs support INT4 and INT2 operations, enabling 8-16x compression. With QAT, 4-bit models now achieve accuracy within 1-2% of FP16.
Speculative decoding: For longer sentences, speculative decoding uses a small draft model to propose tokens while a larger model verifies in parallel—doubling effective generation speed.
Mixture of Experts (MoE): MoE transformers activate only relevant “expert” subnetworks per token, reducing effective compute by 3-10x. MoE is particularly promising for translation across many language pairs.
On-device training: The next frontier is on-device personalization—adapting translation models to user vocabulary, style, and frequently used phrases without cloud data transfer.
Conclusion
Real-time on-device translation was once a contradiction: real-time required cloud compute, but cloud introduced unacceptable latency and privacy compromises. Transformer model compression—through quantization, pruning, and distillation—has resolved this tension.
Today, compressed transformers running on mobile NPUs deliver sub-second latency, hour-plus battery life, and complete privacy. The models that once required data center GPUs now fit in the palm of a hand. For travelers, business professionals, and anyone navigating multilingual contexts, on-device translation has transformed from aspiration to everyday reality.
The technology will only improve. Smaller models, faster NPUs, and better compression techniques will push latency below 50 ms and expand language coverage to every corner of the globe. The cloud will still have its place for the largest models and most complex tasks. But for the fundamental act of conversation across languages, the translation happens right where it should: on the device, in real time, in private.