The Democratization of Large Language Models
Two years ago, running a large language model on consumer hardware was an exercise in frustration. The models that powered ChatGPT and its competitors were giants—hundreds of billions of parameters demanding data center-scale GPU clusters. Running such a model on a laptop was impossible. Running it on a desktop was barely conceivable.
Today, the landscape has transformed. Thanks to quantization, model compression, architectural innovations, and rapidly advancing consumer hardware, running capable LLMs locally is not just possible—it is becoming the default for privacy-conscious users, developers, and organizations. The question is no longer whether you can run an LLM locally, but which model you should run given your hardware constraints.
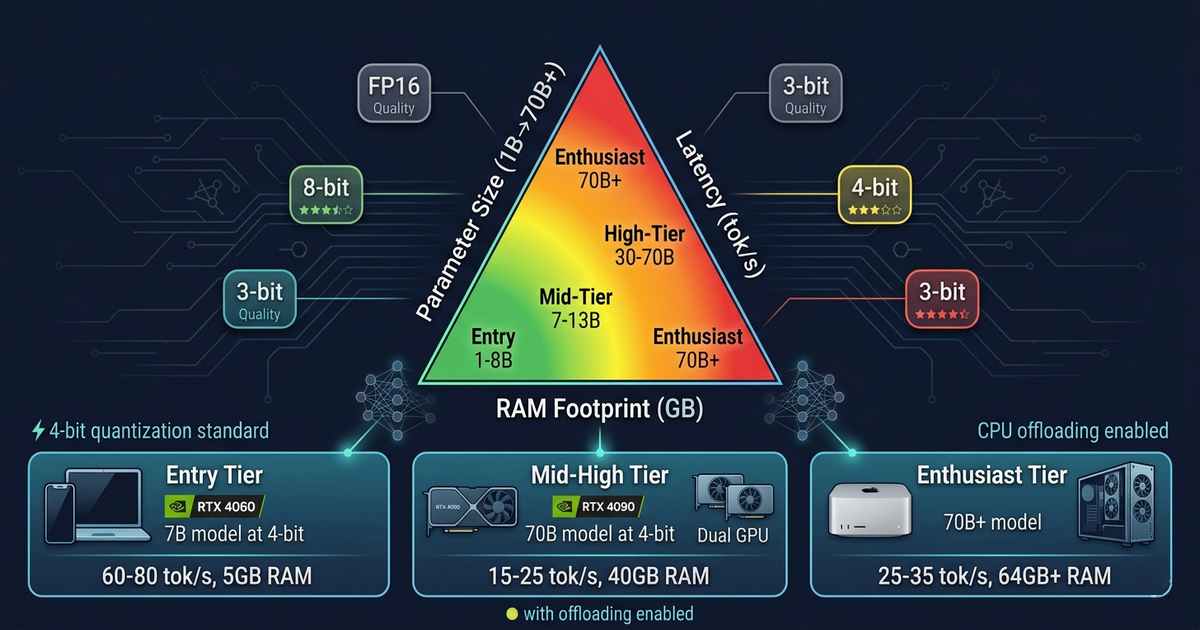
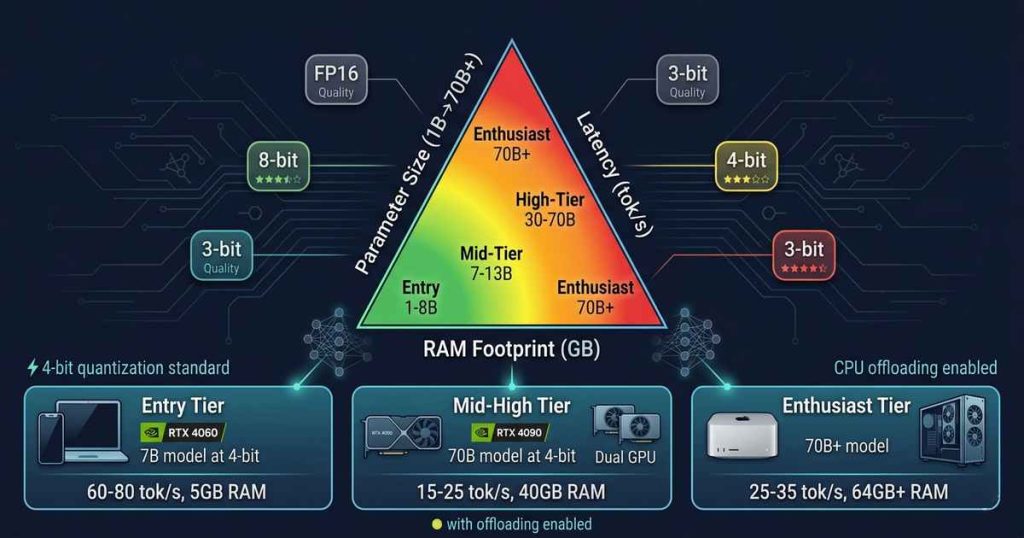
The trade-off space is defined by three interdependent variables: parameter size, inference latency, and RAM footprint. Optimizing one inevitably compromises the others. Understanding these trade-offs is essential for anyone deploying local LLMs—whether on a high-end workstation, a gaming laptop, or a Raspberry Pi.
The Parameter Size Spectrum
Parameter count remains the most visible metric of model capability. More parameters generally means more knowledge, more nuanced reasoning, and better performance on complex tasks. But the relationship is not linear, and raw parameter count tells only part of the story.
Small Models (1B–7B Parameters)
The small model category has exploded in capability. Models like Microsoft’s Phi-3 (3.8B), Google’s Gemma (2B and 7B), Meta’s Llama 3.1 (8B), and Alibaba’s Qwen 2.5 (7B) demonstrate that well-trained models in this range can handle a surprising range of tasks.
Use cases: Text summarization, code completion, basic question answering, lightweight agents, edge deployments.
Hardware targets: Smartphones, Raspberry Pi-class devices, low-power laptops.
RAM footprint: 1–6 GB (quantized).
The Phi-3-mini (3.8B) achieves performance comparable to much larger models on reasoning benchmarks, demonstrating that training data quality and architecture matter as much as raw parameter count. For many everyday tasks, a well-tuned 7B model running at 4-bit quantization is indistinguishable from cloud-hosted alternatives.
Medium Models (8B–20B Parameters)
The medium category represents the sweet spot for most consumer hardware. Models like Llama 3.1 (8B, 70B), Qwen 2.5 (7B, 14B, 32B), and Mistral’s Mixtral (8x7B) offer strong reasoning capabilities while remaining feasible on consumer GPUs.
Use cases: Complex reasoning, multi-turn conversations, coding assistance, local RAG systems.
Hardware targets: Gaming laptops with 8-12GB VRAM, mid-range desktops, MacBooks with M-series chips.
RAM footprint: 4–12 GB (quantized).
The 8B parameter class has become the workhorse of local LLM deployment. Models in this range fit comfortably within the 8-12GB VRAM available on consumer GPUs like the NVIDIA RTX 3060, 4060, or 4070 series. With 4-bit quantization, a 7B model occupies approximately 4-5 GB of memory, leaving room for context and system overhead.
Large Models (30B–70B Parameters)
Models in this range—Llama 3 70B, Qwen 2.5 72B, Mistral Large—approach the capability frontier of open-source LLMs. They rival or exceed GPT-3.5 performance and approach GPT-4 on many benchmarks. But they demand substantial hardware.
Use cases: Complex agentic workflows, advanced coding, sophisticated reasoning, research.
Hardware targets: Dual GPU setups, high-end Mac Studio, cloud instances.
RAM footprint: 20–45 GB (quantized).
A 70B model at 4-bit quantization occupies approximately 35-40 GB of memory. This exceeds the VRAM of any consumer GPU (the RTX 4090 offers 24GB). Deployment requires either dual-GPU configurations (e.g., two RTX 3090/4090 cards), Apple Silicon unified memory (Mac Studio with 64GB+), or CPU inference with GPU offloading.
Frontier Models (70B+ Parameters)
Beyond 70B lies the frontier. Models like Llama 3.1 405B and DeepSeek-V3 (671B) represent state-of-the-art open-source capability but remain firmly in data center territory. Running these locally requires multiple high-end GPUs, substantial memory, and significant power consumption.
Use cases: Research, specialized fine-tuning, capability exploration.
Hardware targets: Server clusters, multi-GPU workstations.
RAM footprint: 200+ GB (quantized).
For most users, these models remain accessible only through API endpoints or cloud instances.
Quantization: The Great Enabler
The breakthrough that made local LLMs practical is quantization—reducing the precision of model weights from 16-bit or 32-bit floating point to lower-bit representations. This dramatically reduces memory footprint and can accelerate inference, though with some quality trade-offs.
Quantization Levels
| Precision | Bits per Parameter | RAM per 1B Params | Typical Use |
|---|---|---|---|
| FP16/BF16 | 16 | 2 GB | Maximum quality, high-end GPUs |
| 8-bit (INT8) | 8 | 1 GB | Good quality, balanced |
| 4-bit (INT4) | 4 | 0.5 GB | Good quality, most common |
| 3-bit (INT3) | 3 | 0.375 GB | Moderate quality, extreme compression |
| 2-bit (INT2) | 2 | 0.25 GB | Reduced quality, edge deployments |
The most common quantization formats—GGUF (for CPU/GPU hybrid), GPTQ (for GPU), and EXL2 (for GPU)—offer different trade-offs. GGUF has become the default for consumer deployment due to its ability to split layers between CPU and GPU, enabling larger models on memory-constrained systems.
Quantization Quality Impact
The quality degradation from quantization varies by model and task. For 4-bit quantization, most benchmarks show a 1-3% degradation in perplexity—imperceptible for most applications. At 3-bit, degradation becomes noticeable but remains acceptable for many use cases. At 2-bit, quality loss is significant, and model collapse becomes a risk for some architectures.
The key insight: a well-quantized 8B model at 4-bit often outperforms a 3B model at 16-bit on the same hardware. Quantization enables a higher parameter count within fixed memory constraints, and the parameter count advantage typically outweighs the precision loss.
Latency: The User Experience Dimension
Latency—the time between prompt submission and response completion—determines the user experience of local LLMs. Three factors dominate latency: prompt processing speed, token generation speed, and memory bandwidth.
Prompt Processing (Prefill)
During prompt processing, the model must compute attention over the entire input sequence. This phase is compute-bound, scaling with the number of prompt tokens and model size. On consumer GPUs, prompt processing rates range from hundreds to thousands of tokens per second for small models, dropping to tens of tokens per second for large models.
For long contexts—say, processing a 100,000-token document—prompt processing can dominate total latency. Systems using RAG (retrieval-augmented generation) mitigate this by limiting context length, keeping prompt processing times manageable.
Token Generation (Decoding)
Once processing begins, the model generates tokens one at a time. This phase is memory bandwidth bound—the limiting factor is how fast the GPU or CPU can move model weights from memory into compute units.
On consumer hardware, token generation speeds vary dramatically:
| Hardware | 7B Model (4-bit) | 13B Model (4-bit) | 70B Model (4-bit) |
|---|---|---|---|
| RTX 4060 (8GB) | 60-80 tok/s | 40-50 tok/s | Not feasible |
| RTX 4090 (24GB) | 120-150 tok/s | 80-100 tok/s | 15-25 tok/s |
| Mac M2 Ultra (64GB) | 80-100 tok/s | 60-80 tok/s | 25-35 tok/s |
| CPU-only (DDR5) | 5-15 tok/s | 3-8 tok/s | 0.5-2 tok/s |
The relationship is straightforward: token generation speed is roughly proportional to memory bandwidth divided by model size. A 70B model at 4-bit requires moving approximately 35GB of weights per generation step. A GPU with 1 TB/s memory bandwidth (like the RTX 4090) can theoretically achieve 28 tokens per second—close to observed performance.
Batch Size and Throughput
For single-user inference, throughput equals token generation speed. For concurrent users or batch processing, throughput scales with batch size until memory capacity is saturated. Consumer deployments typically prioritize single-user latency over throughput.
The Flash Attention Revolution
Flash Attention and its successors have dramatically improved both prompt processing and generation efficiency by optimizing the attention mechanism’s memory access patterns. For long contexts, Flash Attention reduces memory footprint from quadratic to linear in sequence length, enabling models to process hundreds of thousands of tokens on consumer hardware—a capability that did not exist two years ago.
RAM Footprint: The Capacity Constraint
RAM footprint determines which models can run on which hardware. The calculation is straightforward:
Memory Footprint = (Parameters × Bits per Parameter) + Context Overhead
For a 7B model at 4-bit:
- Weights: 7B × 0.5 bytes = 3.5 GB
- KV cache (for 4096 context): ~1 GB
- System overhead: ~0.5 GB
- Total: ~5 GB
For a 70B model at 4-bit:
- Weights: 70B × 0.5 bytes = 35 GB
- KV cache: ~4 GB
- System overhead: ~1 GB
- Total: ~40 GB
Memory Hierarchy Strategies
Consumer hardware offers three memory tiers, each with different characteristics:
GPU VRAM (GDDR6/6X): Highest bandwidth (500-1000 GB/s), lowest capacity (8-24GB). Ideal for model weights and active computation.
Unified Memory (Apple M-series): Good bandwidth (100-400 GB/s), high capacity (16-128GB). Enables running models up to available memory, though bandwidth varies by chip generation.
System RAM (DDR4/DDR5): Moderate bandwidth (50-100 GB/s), high capacity (16-128GB). Viable for inference with CPU offloading, though latency increases significantly.
CPU Offloading and Model Sharding
For models that exceed available VRAM, modern inference engines like llama.cpp and Ollama support CPU offloading—splitting model layers between GPU and system RAM. Layers that fit in VRAM process at GPU speeds; remaining layers process on CPU. The performance impact is proportional to the percentage of layers offloaded.
A 70B model with 20 layers on a 24GB GPU and 60 layers on CPU might achieve 5-10 tokens per second—slow but usable for many applications.
Consumer Hardware Tiers for Local LLMs
Entry Tier (Smartphones, Raspberry Pi, 4GB RAM)
Capability: 1B–3B models at 4-bit
Typical latency: 10-30 tokens per second
Use cases: Basic assistants, offline translation, simple text tasks
The Raspberry Pi 5 can run a 3B parameter model like Phi-3-mini at usable speeds. Mobile devices with NPU acceleration achieve similar performance. The key constraint is memory—models under 4GB footprint are the limit.
Mid Tier (Gaming Laptop, 8-12GB VRAM, 16GB RAM)
Capability: 7B–13B models at 4-bit
Typical latency: 40-80 tokens per second
Use cases: Coding assistants, local RAG, multi-turn conversations
This is the sweet spot for most users. A laptop with RTX 4060 (8GB VRAM) comfortably runs a 7B model entirely on GPU. With 12GB VRAM, 13B models become feasible. The experience is responsive enough for real-time interaction.

High Tier (Desktop, 24GB VRAM, 32-64GB RAM)
Capability: 8B–34B models at 4-bit; 70B models with offloading
Typical latency: 80-150 tokens per second (small models); 15-25 tokens per second (70B)
Use cases: Advanced agents, large context processing, model fine-tuning
A desktop with RTX 4090 (24GB VRAM) represents the current consumer optimum. It runs 34B models entirely on GPU and can offload 70B models with acceptable performance. This configuration handles virtually all local LLM use cases.
Enthusiast Tier (Multi-GPU, Mac Studio, 48GB+ Unified Memory)
Capability: 70B–180B models at 4-bit
Typical latency: 20-40 tokens per second
Use cases: Frontier model evaluation, research, specialized deployments
Dual RTX 3090/4090 cards provide 48GB combined VRAM—enough for 70B models entirely on GPU. Apple Mac Studio with 64-128GB unified memory runs 70B models at impressive speeds due to unified memory architecture eliminating PCIe bottlenecks.
Benchmarking Reality: What to Expect
The following benchmarks represent real-world performance across common configurations. Results assume 4-bit quantization using llama.cpp with default settings.
Llama 3.1 8B (4-bit, ~5GB footprint)
| Hardware | Tokens/Second |
|---|---|
| RTX 4060 (8GB) | 65-75 |
| RTX 4070 (12GB) | 80-90 |
| RTX 4090 (24GB) | 120-140 |
| M3 Max (36GB) | 50-60 |
| CPU-only (DDR5) | 8-12 |
Qwen 2.5 14B (4-bit, ~8GB footprint)
| Hardware | Tokens/Second |
|---|---|
| RTX 4070 (12GB) | 45-55 |
| RTX 4090 (24GB) | 75-90 |
| M3 Max (36GB) | 35-45 |
| CPU-only | 4-6 |
Llama 3.1 70B (4-bit, ~40GB footprint)
| Hardware | Tokens/Second |
|---|---|
| RTX 4090 (24GB) + offload | 5-8 |
| Dual RTX 3090 (48GB) | 18-25 |
| M2 Ultra (64GB) | 25-35 |
| M3 Max (64GB) | 15-20 |
| CPU-only (128GB DDR5) | 1-2 |
Optimization Techniques Beyond Quantization
Speculative Decoding
Speculative decoding accelerates generation by using a small “draft” model to predict multiple tokens, then verifying them with the large model in parallel. For models with significant size disparity, speculative decoding can double or triple token generation speed. The technique works best when draft and target models share tokenizers—as with Llama families.
KV Cache Optimization
The KV cache stores attention keys and values from previous tokens to avoid recomputation. At long context lengths, the KV cache can exceed model weight memory. Techniques like KV cache quantization (to 8-bit or 4-bit) and sliding window attention reduce this overhead. For a 70B model with 128K context, optimized KV cache reduces memory footprint from ~100GB to ~10GB.
Prompt Caching
Many applications reuse system prompts or repeated instructions. Prompt caching stores processed prompt embeddings, eliminating recomputation for identical prefixes. This dramatically improves latency for multi-turn conversations where system prompts remain constant.
Continuous Batching
For server deployments, continuous batching processes multiple inference requests concurrently, maximizing GPU utilization. While less relevant for single-user local inference, continuous batching enables consumer GPUs to serve multiple users or multiple agent instances simultaneously.
The Decision Framework: Choosing the Right Model
Given your hardware and use case, how do you choose?
Step 1: Determine your memory ceiling.
Calculate available memory for model weights. For GPU-only, this is VRAM minus 2-3GB for system overhead. For CPU offloading, this is total system RAM available.
Step 2: Select the largest model that fits within memory at 4-bit quantization.
A 7B model fits in 8GB VRAM. A 13B model fits in 12GB. A 34B model fits in 20GB. A 70B model requires 40GB.
Step 3: Consider quality vs. speed trade-offs.
If the largest model yields unacceptable latency, consider a smaller model at higher precision (8-bit) or a different architecture optimized for your use case.
Step 4: Test with your specific workload.
Benchmarks provide guidance; real-world performance varies with prompt length, generation length, and specific hardware configurations.
The Future: What’s Coming
The trajectory of local LLMs is clear: capability is increasing faster than hardware requirements. Several trends will accelerate this:
Better quantization: 3-bit quantization with minimal quality loss is approaching. New techniques like AQLM (Additive Quantization for Language Models) and QuIP# promise further compression with preserved capability.
Architectural efficiency: Mixture-of-Experts (MoE) models like Mixtral and DeepSeek-V2 activate only a subset of parameters per token, reducing effective compute without reducing capability. A 70B MoE model may use only 12B parameters per inference, dramatically improving latency on consumer hardware.
Hardware acceleration: Next-generation consumer GPUs will offer increased VRAM—NVIDIA’s RTX 5000 series is rumored to include 32GB and 48GB options. Apple’s M-series continues to push unified memory bandwidth. NPU acceleration for transformers is appearing in mobile and laptop chips.
Speculative decoding maturity: As draft models become better optimized, speculative decoding will become the default, potentially doubling effective token generation speeds across all hardware tiers.
Conclusion: The Local LLM Reality
Running LLMs locally on consumer hardware is no longer an aspiration—it is a practical reality. The trade-off triangle of parameter size, latency, and RAM footprint defines a solution space where meaningful capability is accessible at every hardware tier.
For users with modest hardware, well-tuned 7B models running at 4-bit provide capable assistants, code completion, and local RAG. For those with high-end desktops, 70B models approach cloud-based frontier capabilities. And across all tiers, quantization, optimization techniques, and rapidly advancing open-source models continue to push the boundaries of what is possible.
The implications extend beyond convenience. Local LLMs offer privacy without compromise—data never leaves your device. They offer independence from API costs and rate limits. They offer control—fine-tuned models, specialized capabilities, and the ability to run indefinitely without external dependencies.
The era of local LLMs has arrived. The trade-offs are understood. The hardware exists. The only question remaining is: what will you build?