Running LLMs Locally: Parameter Size vs Latency vs RAM Footprint on Consumer Hardware
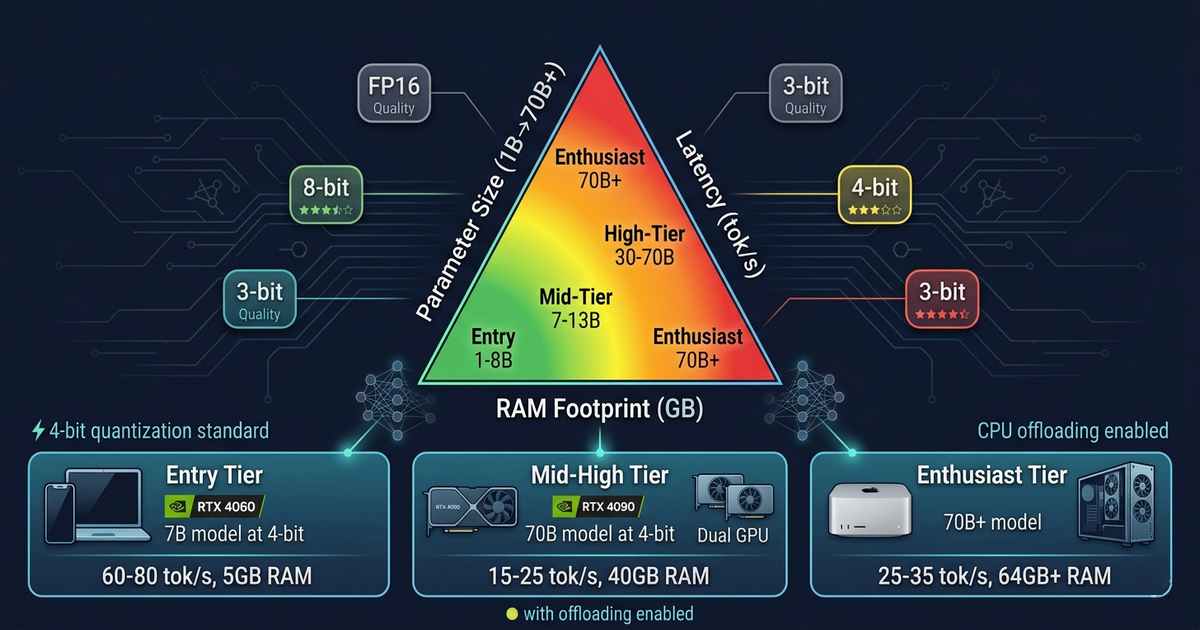
The Democratization of Large Language Models Two years ago, running a large language model on consumer hardware was an exercise in frustration. The models that powered ChatGPT and its competitors were giants—hundreds of billions of parameters demanding data center-scale GPU clusters. Running such a model on a laptop was impossible. Running it on a desktop … Read more