Real-Time On-Device Translation: Transformer Model Compression for Mobile NPUs
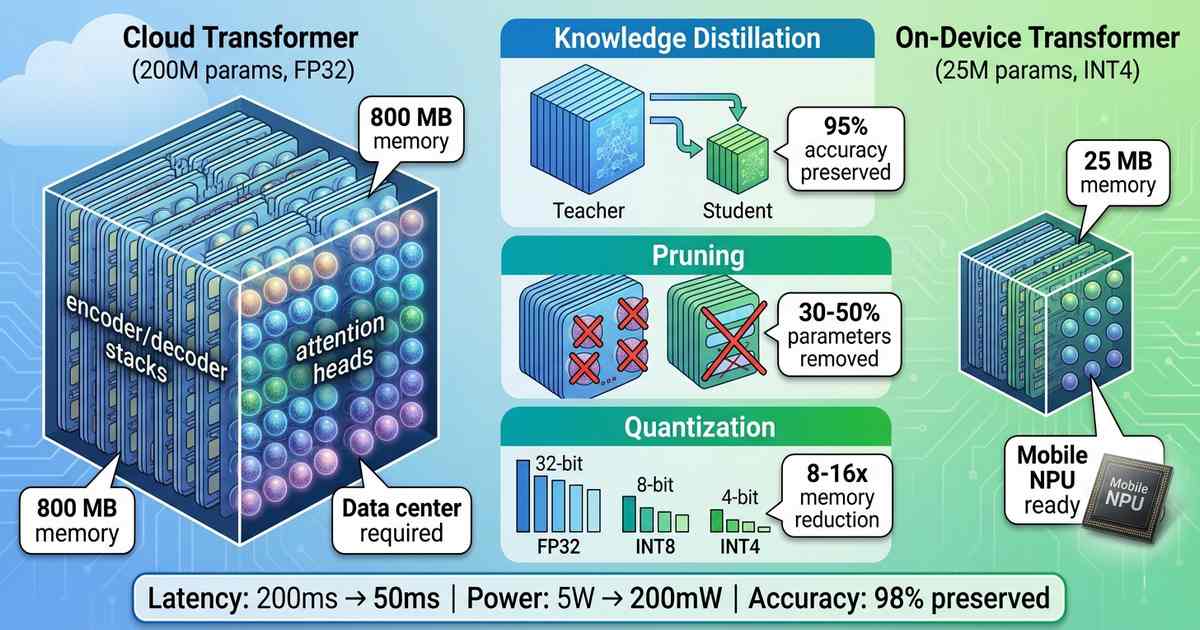
The Privacy-Latency Trade-Off For years, real-time translation lived in the cloud. Smartphone users spoke into their devices, audio traveled to remote servers, large language models processed the text, and translations streamed back. The results were impressive in quality but problematic in practice: latency varied with network conditions, privacy demanded sending conversations to third-party servers, and … Read more

